Embodied Intelligence: building accurate, efficient, and generalizable embodied large models that perceive, reason, and act in the physical world, such as Vision-Language-Action (VLA) models, Diffusion Policies (DP), World Action Models (WAM), etc.
Efficient Artificial Intelligence: making powerful large models available to everyone under limited compute, such as efficient inference and compression for large language models (LLMs), including token compression, network pruning, quantization, sparsity, caching, etc.
🎓 Open to research collaboration. Efficient AI · Embodied Intelligence · VLA · Model Acceleration [CV][Scholar][Email]
📰 Latest News
Jun 2026AcceptRoboStream is accepted by ECCV 2026 — see you in Malmö 🇸🇪
May 2026arXivElegantVLA is released — welcome to discuss! 💬
May 2026AcceptSAG is accepted by ICML 2026 — see you in Seoul 🇰🇷
Feb 2026AcceptTTS & VVS are accepted by CVPR 2026 — see you in Denver 🇺🇸
Jan 2026AcceptSP-VLA & BAC are accepted by ICLR 2026 — see you in Rio 🇧🇷
Dec 2025arXivTS-DP is released — welcome to discuss! 💬
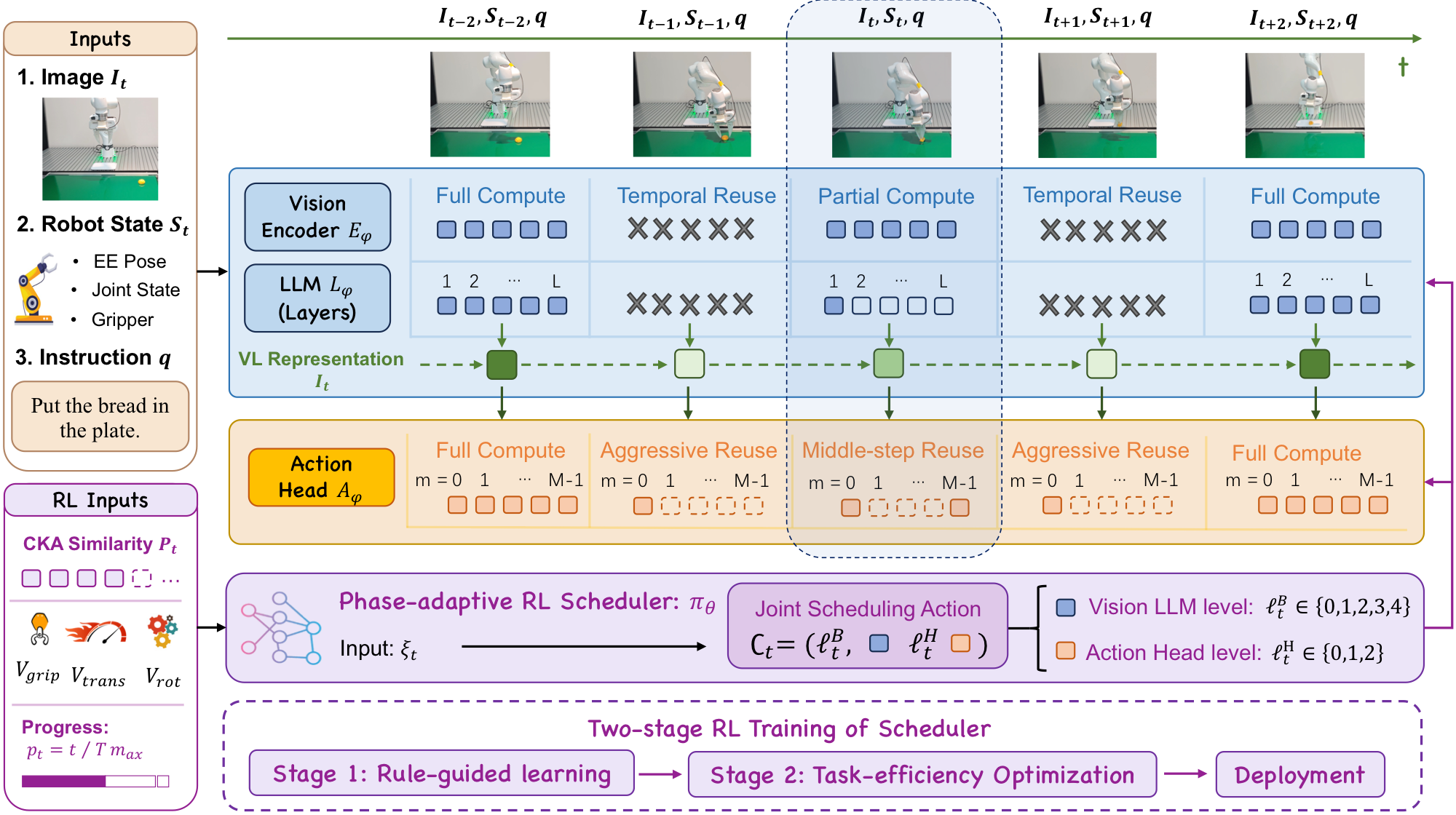
Vision-Language-Action (VLA) models are powerful for generalist robotic control but slow, since large vision-language backbones and iterative action heads run at every control step, and prior acceleration uses fixed rules that ignore the non-uniform reasoning demands of sequential control. Inspired by human motor control — where resources concentrate on goal-sensitive stages — ElegantVLA learns when to think. It is a training-free, plug-in phase-adaptive framework whose lightweight scheduler watches temporal representation similarity, robot-motion cues, and episode progress to jointly allocate compute across the vision encoder, LLM, and action head: a five-level Vision–LLM mode (full recomputation to multi-step temporal reuse) and a three-level denoising mode (reuse during stable motion, full refinement at goal-sensitive stages). On GR00T it reaches up to 2.55× speedup, on CogACT 3.77×, and in real-world GR00T tasks it cuts computation 2.18× while raising control frequency from 13.8 to 26.3 Hz — preserving or improving task success.
Y. Li*, H. Liu, K. Ji, Y. Meng, J. Fan, Y. Wang, S. Qin, C. Wu, S.-T. Xia, Z. Wang
ElegantVLA accelerates the full VLA pipeline end to end: by analyzing redundancy in both high-level semantics and action generation, it adaptively schedules computation across every module — the vision encoder, LLM, and action head — for extreme speedups.
⚡ up to 2.55× (GR00T) · 3.77× (CogACT) · real-world (Franka) 13.8→26.3 Hz
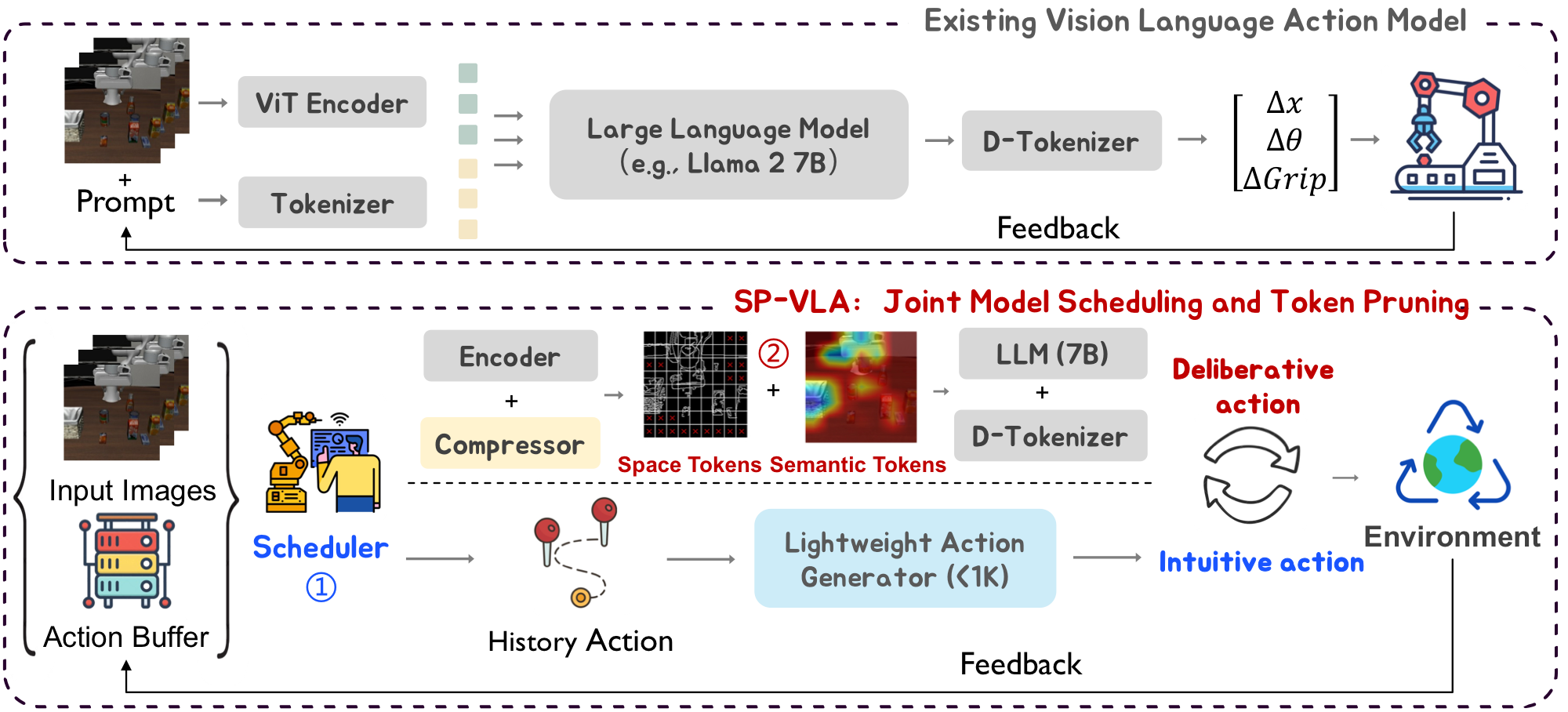
Vision-Language-Action (VLA) models deliver strong control but are too slow for real-time robotics. SP-VLA accelerates them by removing two kinds of redundancy that prior compression overlooks: temporal redundancy across sequential actions and spatial redundancy in visual input. An action-aware scheduler routes intuitive steps to a lightweight generator and deliberative ones to the full VLA model, while a spatio-semantic dual-aware token pruner keeps only the most informative tokens. Together they achieve 1.5× lossless speedup on LIBERO and 2.4× on SimplerEnv, with up to 6% average performance gain.
Y. Li*, Y. Meng, Z. Sun, K. Ji, C. Tang, J. Fan, X. Ma, S.-T. Xia, Z. Wang, W. Zhu
SP-VLA is the first method to exploit temporal redundancy in VLA inference: it reads the end-effector's speed to separate intuitive from deliberative steps, delegating cheap steps to a lightweight generator and reserving the full VLA model for critical ones — achieving lossless acceleration.
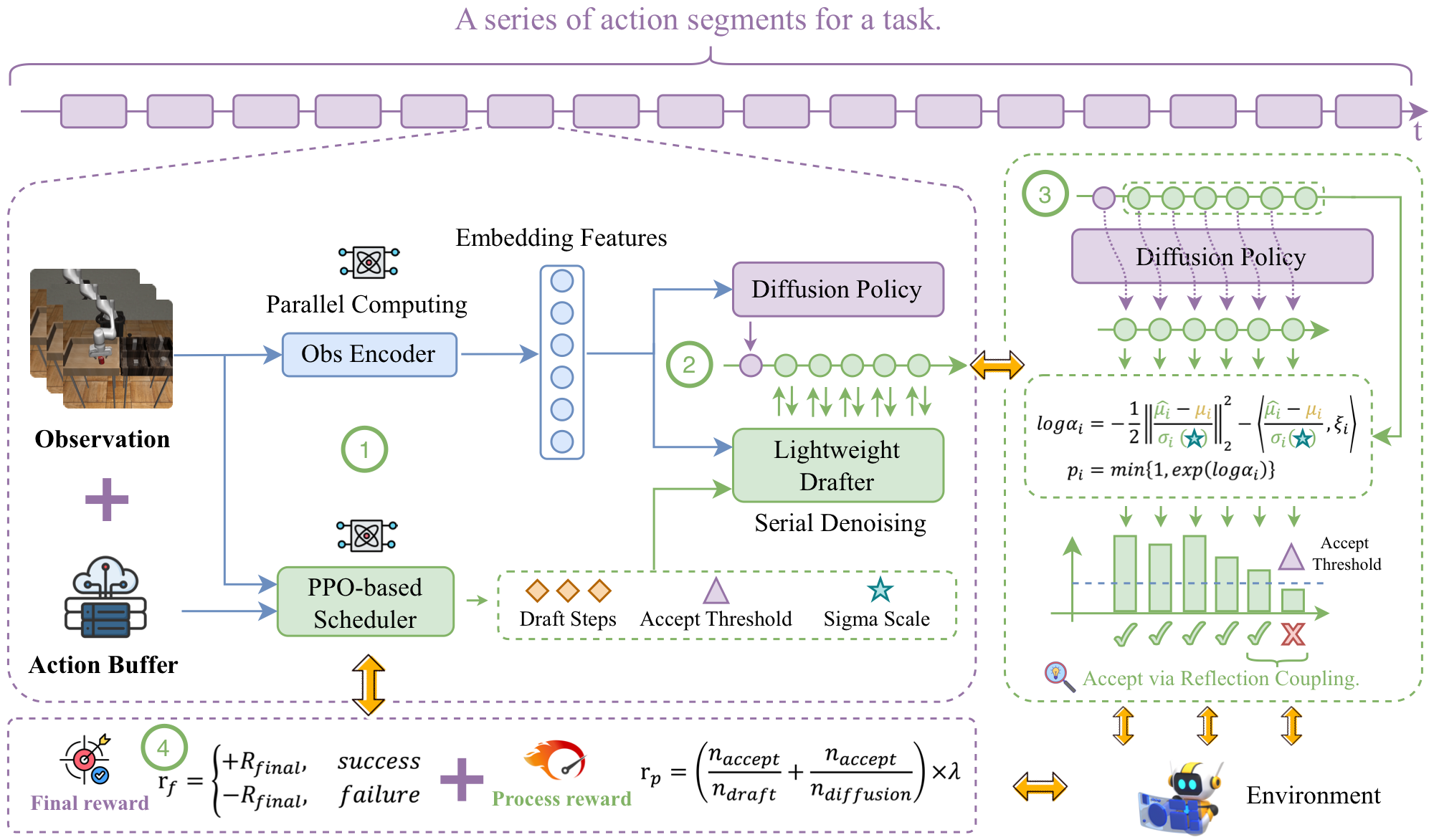
Diffusion Policy (DP) excels at embodied control but is slow due to iterative denoising, while embodied tasks demand dynamic, adaptive computation. Static lossy methods (e.g., quantization) cannot handle this, whereas speculative decoding offers a lossless, adaptive—yet underexplored—alternative. TS-DP is the first framework to enable temporally-adaptive speculative decoding for DP: a distilled Transformer drafter imitates the base model to replace costly denoising calls, and an RL-based scheduler adjusts speculative parameters to match time-varying task difficulty. Across diverse embodied environments, TS-DP achieves up to 4.17× faster inference with over 94% accepted drafts, reaching 25 Hz real-time control without performance degradation.
Y. Li*, J. Feng, Y. Meng, K. Ji, C. Tang, X. Wen, S.-T. Xia, Z. Wang, W. Zhu
TS-DP is the first to bring lossless speculative decoding to Diffusion Policy, with an RL scheduler that adapts the speculative computation to time-varying task difficulty in embodied control.
⚡ up to 4.17× faster · >94% drafts accepted · 25 Hz real-time (Franka) · lossless
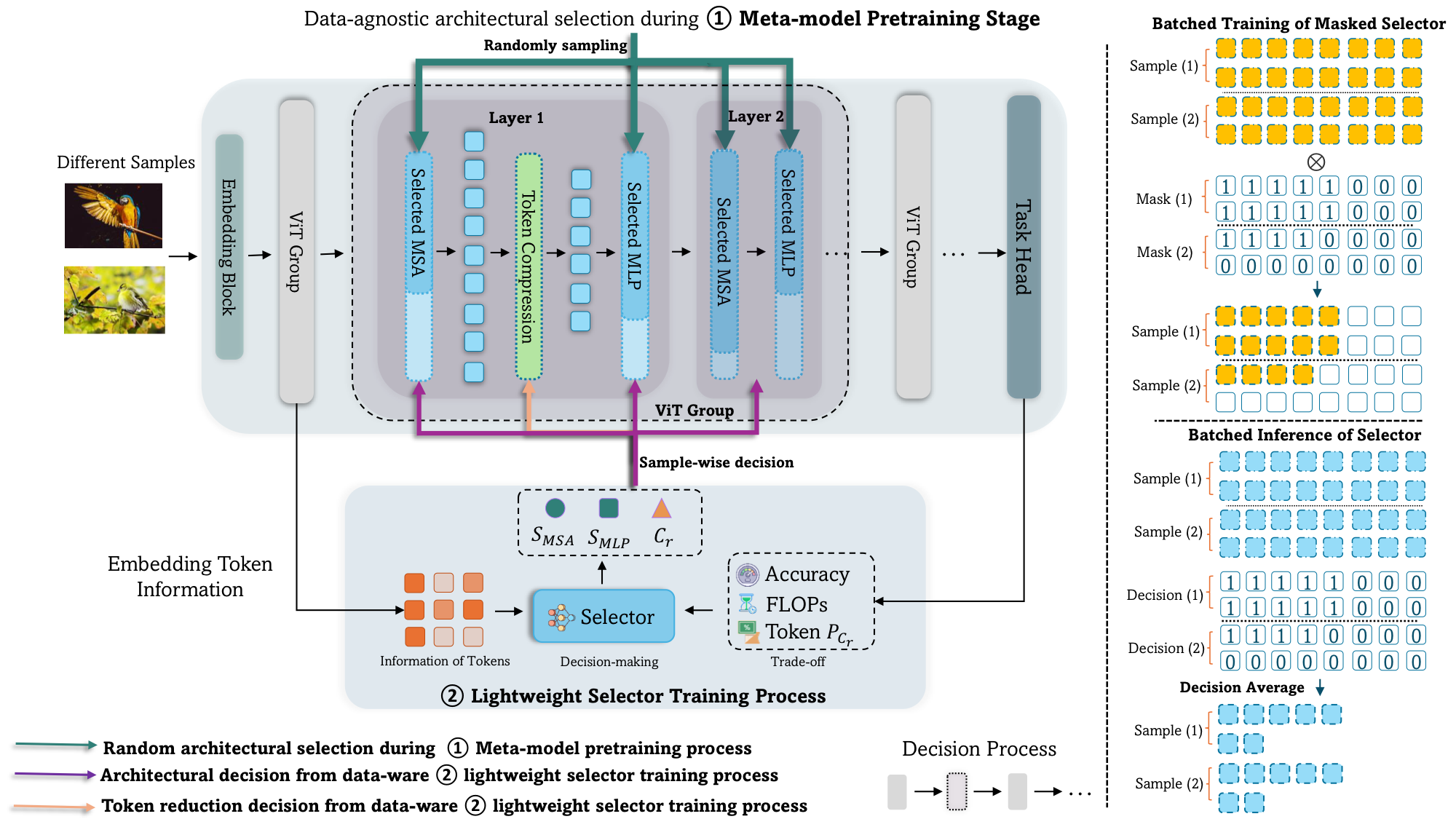
Vision Transformers are costly due to model size and quadratic token complexity, yet existing compression is static and single-domain — fixing a sparsity ratio or treating architecture and token selection separately — causing sharp accuracy drops under aggressive rates. PRANCE jointly optimizes activated channels and token count per input: a weight-sharing meta-network supports arbitrary channel widths for attention/MLP layers, and a lightweight PPO selector navigates the huge (~10^14) decision space, trained via a 'Result-to-Go' mechanism that casts ViT inference as a Markov decision process. PRANCE cuts FLOPs by ~50% while retaining only ~10% of tokens at lossless Top-1 accuracy, and is compatible with pruning, merging, and sequential pruning-merging.
Y. Li*, C. Tang*, Y. Meng, J. Fan, Z. Chai, X. Ma, Z. Wang, W. Zhu
PRANCE performs per-input joint optimization of computational redundancy from both the data and the model perspectives — co-reducing tokens and pruning channels — to push ViT acceleration to the extreme.
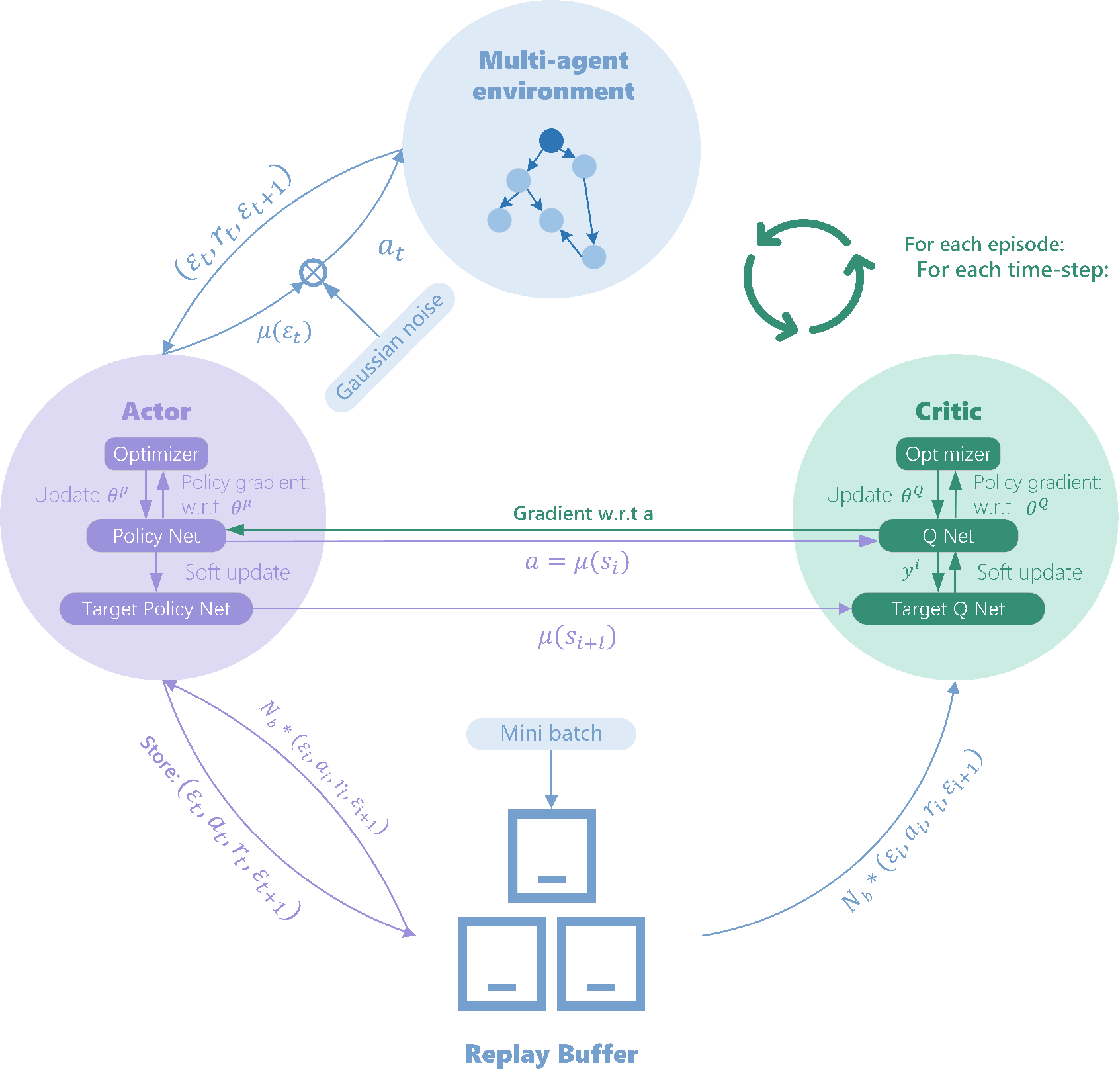
Modeling engineering systems is costly because parameters drift with temperature, component aging, etc. This work proposes a data-driven, model-free optimal controller based on Deep Deterministic Policy Gradient (DDPG) for continuous-time leader-following multi-agent consensus. Two neural networks fit the state and action spaces to avoid the dimensional explosion of time-consuming state iteration; the controller reaches consensus from only the consensus error, requires no initial admissible policy, and self-learns in real time as system parameters change, with minimal energy consumption. Convergence and stability are proven and verified in simulation.
Y. Li*, Z. Liu, G. Lan, M. Sader, Z. Chen
A data-driven, model-free optimal controller based on DDPG for continuous-time leader-following multi-agent consensus — it learns optimal control online from observations alone, removing the need for an accurate system model or any initial admissible policy.
🤖 DDPG-based optimal consensus for multi-agent systems
Vision-Language Models (VLMs) are increasingly used as high-level planners for robotic manipulation, but they struggle on long-horizon tasks that demand persistent spatial understanding and temporal memory across many steps. RoboStream is a training-free framework that augments VLM planners with explicit spatio-temporal reasoning and memory: Spatio-Temporal Fusion Tokens compress and carry historical visual-spatial context across the rollout, while a Causal Spatio-Temporal Graph models how scene entities and actions evolve over time, enabling consistent, memory-aware planning. Without any additional training, RoboStream improves robustness and success on long-horizon robotic manipulation.
Y. Huang, J. Wu, W. Bu, Z. Xiong, G. Jiang, Y. Li, K. Ji, S. Xie, Y. Huang, C. Wu, J. Jiang, Z. Wang
RoboStream is a training-free framework that equips VLM planners with persistent spatio-temporal reasoning and memory — via Spatio-Temporal Fusion Tokens and a Causal Spatio-Temporal Graph — for robust long-horizon robotic manipulation.
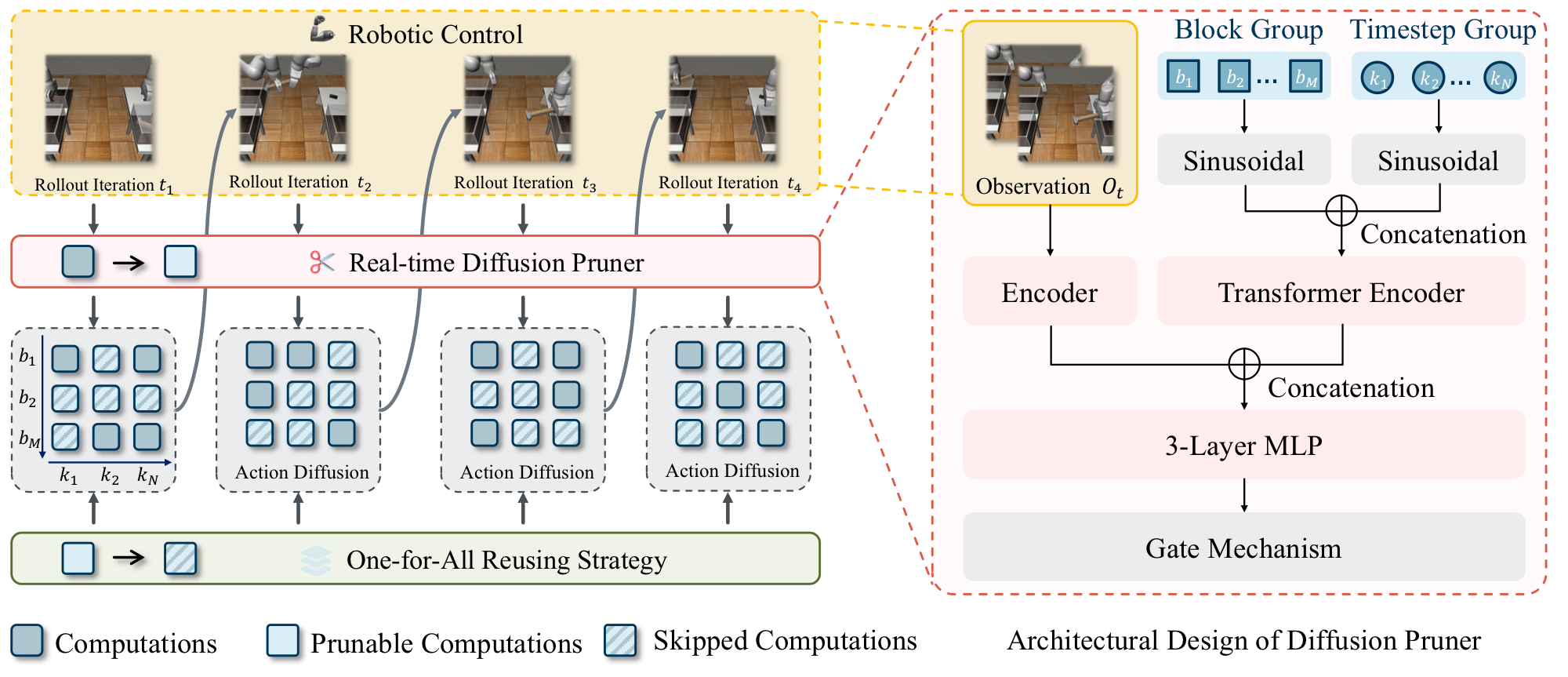
Diffusion Policy models multi-modal action distributions well but its multi-step denoising is too slow for real-time visuomotor control, and existing caching accelerators use static schedules that don't adapt to robot-environment dynamics. SAG (Sparse ActionGen) enables extremely sparse action generation via a rollout-adaptive prune-then-reuse mechanism: it first identifies prunable computations globally, then reuses cached activations to substitute them. An observation-conditioned diffusion pruner — designed to be highly parameter- and inference-efficient — captures rollout dynamics for environment-aware adaptation, and a one-for-all reuse strategy reuses activations across both timesteps and blocks in a zig-zag manner to minimize global redundancy. Across multiple robotic benchmarks, SAG achieves up to 4× generation speedup without sacrificing performance.
K. Ji, J. Zhou, Y. Meng, Y. Li, H. Cui, Z. Wang
SAG accelerates Diffusion Policy to real time via a rollout-adaptive prune-then-reuse scheme — an observation-conditioned pruner identifies prunable computations on the fly, and a one-for-all strategy reuses activations across timesteps and blocks.
⚡ up to 4× generation speedup · no performance loss
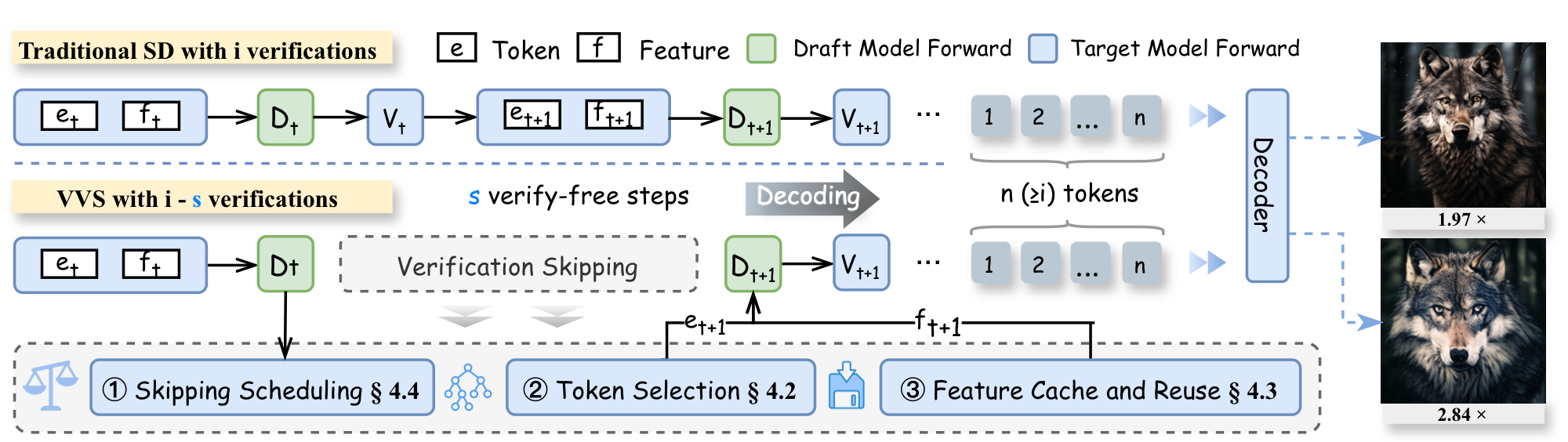
Visual autoregressive (AR) generation is strong for image synthesis but slow due to next-token prediction, and speculative decoding's 'draft one step, then verify one step' paradigm prevents a direct reduction in forward passes. Leveraging the interchangeability of visual tokens, VVS explores verification skipping for the first time to explicitly cut target-model forward passes. It integrates three modules: (1) a verification-free token selector with dynamic truncation, (2) token-level feature caching and reuse, and (3) fine-grained skipped-step scheduling. VVS reduces target-model forward passes by 2.8× relative to vanilla AR decoding while maintaining competitive generation quality, offering a superior speed-quality trade-off over conventional speculative decoding.
H. Dong, Y. Li, R. Lu, C. Tang, S.-T. Xia, Z. Wang
VVS is the first to bring step-skipping to speculative decoding: by skipping verification steps for visual autoregressive generation, it directly cuts target-model forward passes via a verification-free token selector, feature caching, and skipped-step scheduling.
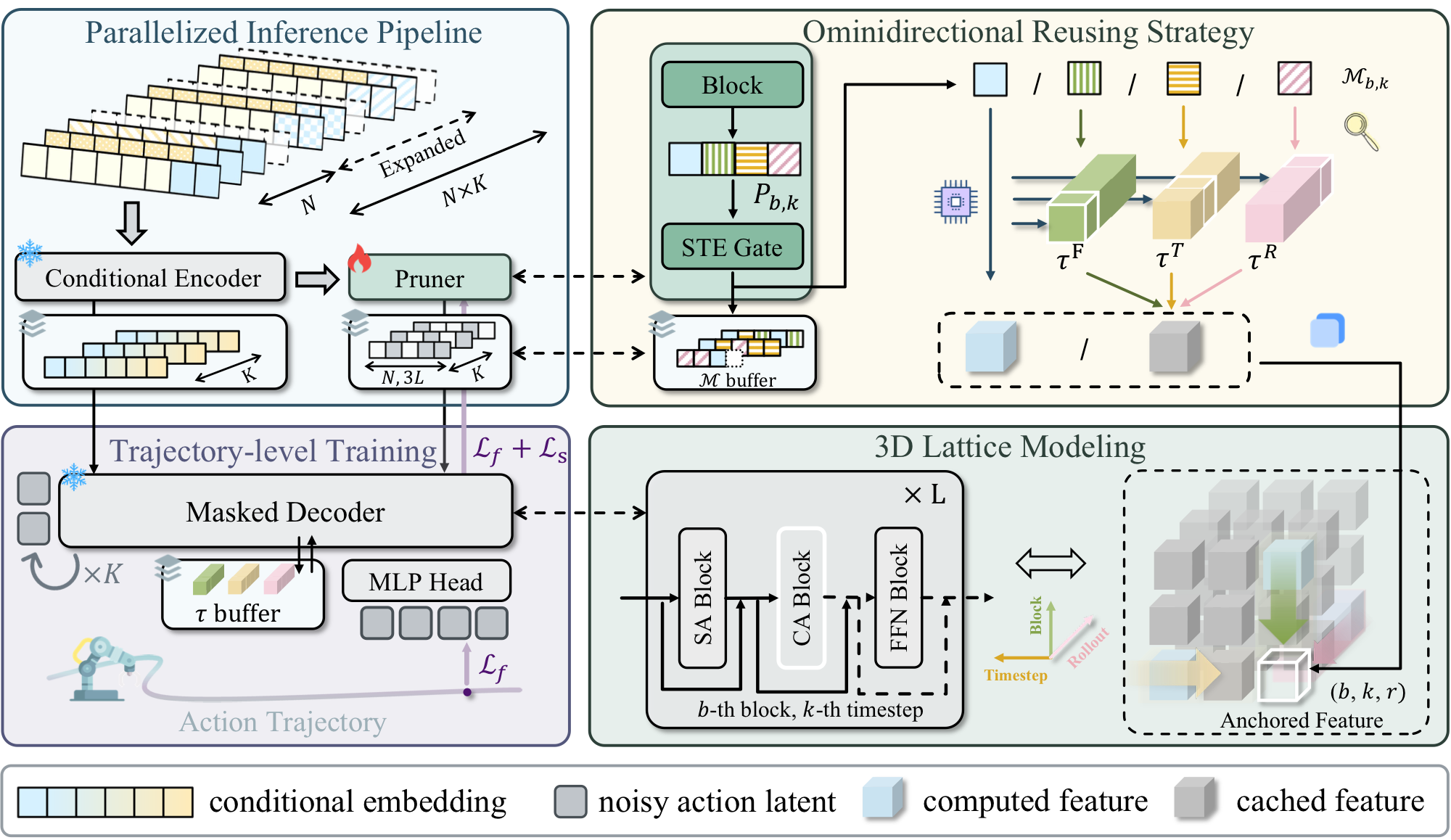
Action diffusion produces high-fidelity actions but is costly due to iterative denoising, and feature-caching accelerators struggle to adapt to the policy dynamics of open-environment rollouts. TTS proposes test-time sparsity: it dynamically predicts prunable residual computations for each model forward at test time. To keep the savings real, a highly parallelized pipeline shares a lightweight pruner with the diffusion transformer and overlaps pruning with decoding (cutting non-decoder delay to milliseconds); an omnidirectional reuse strategy then reaches 95% sparsity by reusing features cached within the current forward, across denoising timesteps, and across rollout iterations. TTS reduces FLOPs by 92% and accelerates action generation by 5×, achieving lossless performance at 47.5 Hz.
K. Ji, Y. Meng, J. Zhou, Y. Li, C. Tang, Z. Wang
TTS accelerates action diffusion to real time via test-time sparsity — dynamically predicting prunable computations at each forward, with a parallelized pipeline and an omnidirectional feature-reuse strategy reaching 95% sparsity.
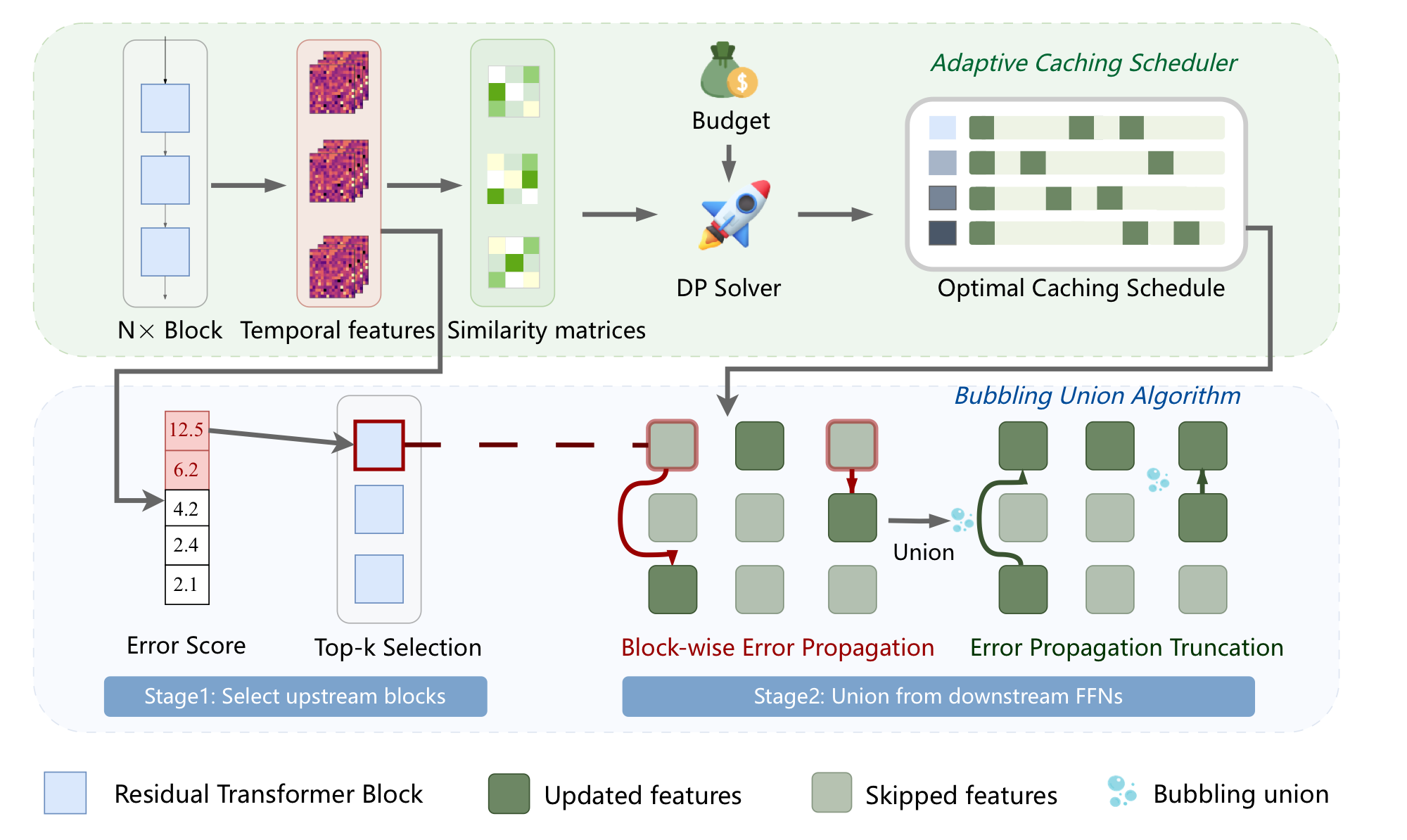
Diffusion Policy has strong visuomotor modeling ability but its high denoising cost is impractical for real-time robotic control, and existing diffusion accelerators fail to generalize to it due to architectural and data divergences. BAC (Block-wise Adaptive Caching) accelerates Diffusion Policy by caching intermediate action features, achieving lossless acceleration by adaptively updating and reusing cached features at the block level — based on the observation that feature similarities are non-uniform over time and block-specific. An Adaptive Caching Scheduler picks optimal update timesteps by maximizing global feature similarity; since per-block scheduling causes error surges from inter-block error propagation (especially in FFN blocks), a Bubbling Union Algorithm truncates these errors by updating high-error upstream blocks before downstream FFNs. As a training-free plugin compatible with transformer-based Diffusion Policy and VLA models, BAC delivers up to 3× inference speedup for free.
K. Ji, Y. Meng, H. Cui, Y. Li, J. Zhou, S. Hua, L. Chen, Z. Wang
BAC is a training-free plugin that accelerates Diffusion Policy by caching intermediate action features per transformer block — each block gets its own optimal update schedule, with a Bubbling Union Algorithm to stop cross-block cache-error propagation.
⚡ up to 3× inference speedup · training-free plugin · lossless
Happy to discuss research, internships, or collaborations. Best reached by email. 📧 liye23@mails.tsinghua.edu.cn · 🏛 Tsinghua Shenzhen International Graduate School (SIGS) CV · 💼 LinkedIn · 🔬 ORCID