
Test-time Sparsity for Extreme Fast Action Diffusion
Published in IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026 (CVPR 2026), 2026
Recommended citation: Kangye Ji, Yuan Meng, Jianbo Zhou, Ye Li, Chen Tang, Zhi Wang. "Test-time Sparsity for Extreme Fast Action Diffusion." CVPR 2026. https://openaccess.thecvf.com/content/CVPR2026/html/Ji_Test-time_Sparsity_for_Extreme_Fast_Action_Diffusion_CVPR_2026_paper.html
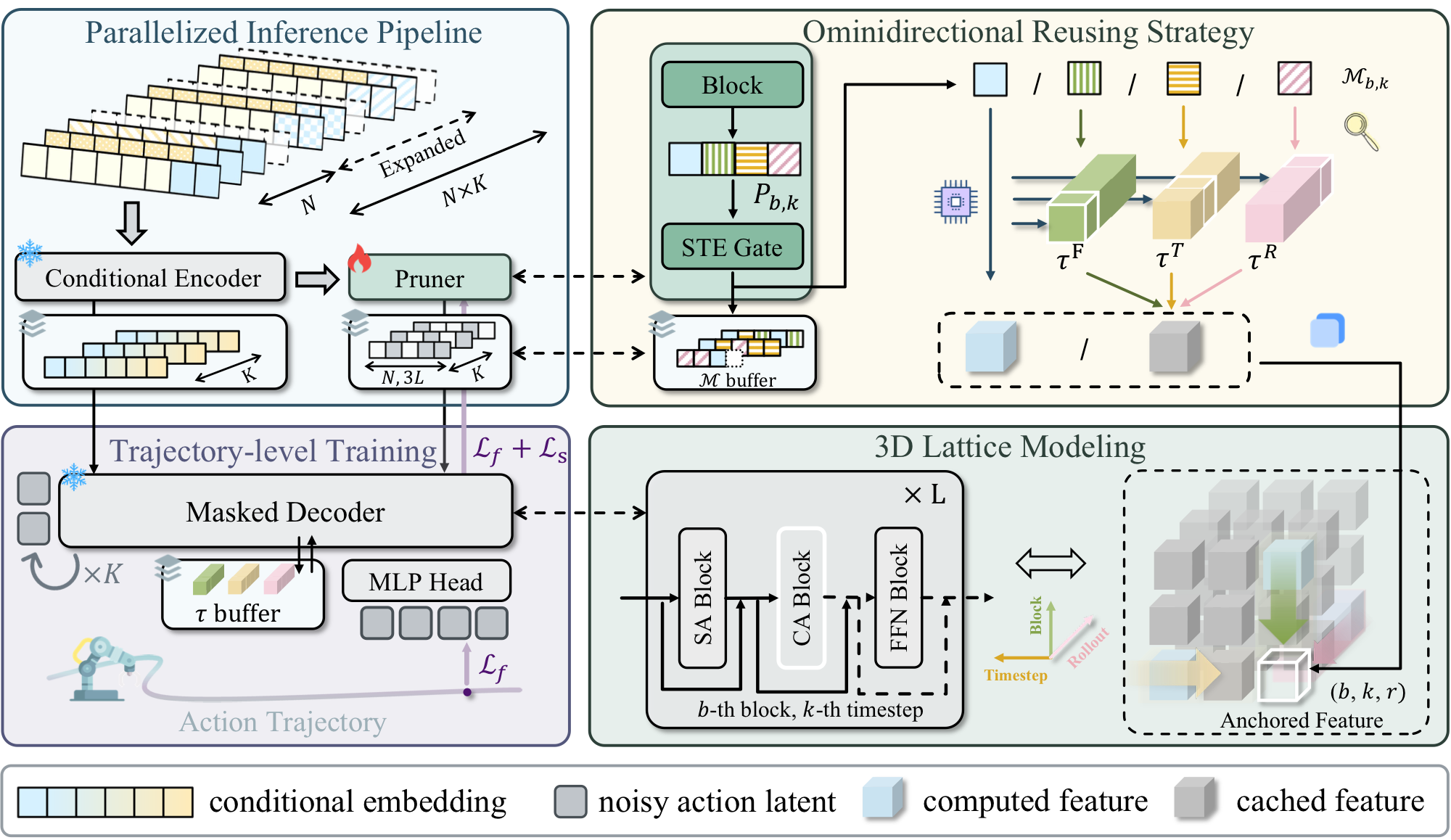
Action diffusion excels at high-fidelity action generation but incurs heavy computational cost due to iterative denoising. Existing accelerators that reuse cached features struggle to adapt to the policy dynamics arising from diverse perceptions and multi-round rollouts in open environments.
TTS introduces test-time sparsity: it accelerates action diffusion by dynamically predicting prunable residual computations for each model forward at test time. Two bottlenecks are addressed:
- Parallelized inference pipeline. A lightweight pruner shares the encoder with the diffusion transformer; encoding and pruning are decoupled from the autoregressive denoising loop (all timesteps processed in parallel), and the pruner is overlapped with decoder inference via asynchronism — minimizing non-decoder delay to milliseconds.
- Omnidirectional reuse. Achieves 95% sparsity by selectively reusing features cached from the current forward, previous denoising timesteps, and earlier rollout iterations, supervised with only a few sampled trajectories.
TTS reduces FLOPs by 92% and accelerates action generation by 5×, achieving lossless performance at 47.5 Hz.