
PRANCE: Joint Token-Optimization and Structural Channel-Pruning for Adaptive ViT Inference
Published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026, 2025
Recommended citation: Ye Li, Chen Tang, Yuan Meng, Jiajun Fan, Zenghao Chai, Xinzhu Ma, Zhi Wang, Wenwu Zhu. "PRANCE: Joint Token-Optimization and Structural Channel-Pruning for Adaptive ViT Inference." TPAMI 2026. https://ieeexplore.ieee.org/document/11146899
Vision Transformers (ViTs) are held back by their model size and the quadratic cost in the number of tokens. Existing acceleration is either static (a fixed sparsity ratio) or single-domain (optimizing architecture or token selection in isolation), so it fails to exploit redundancy across both axes and degrades sharply under aggressive compression.
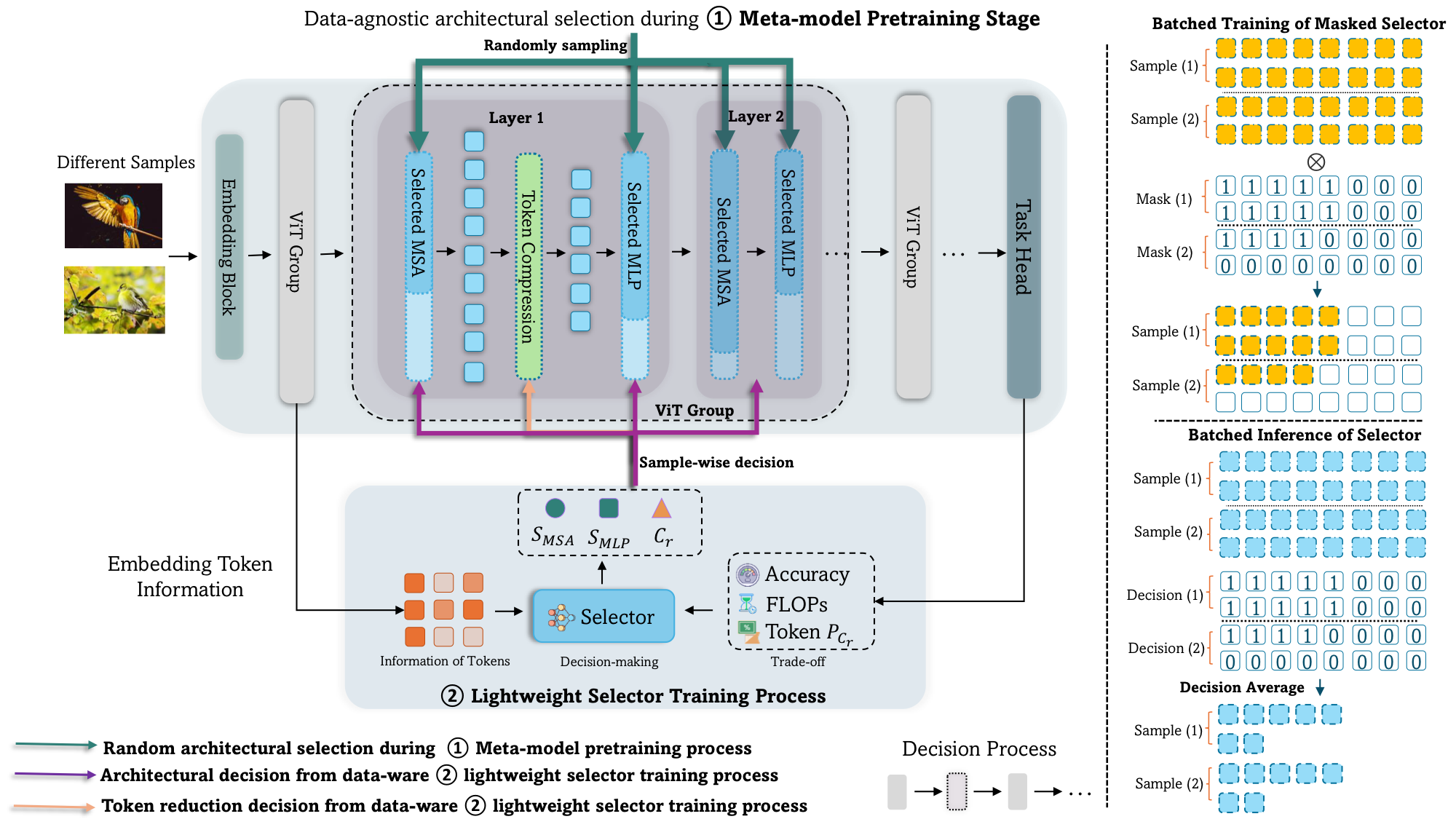
PRANCE jointly optimizes the activated channels and the token count based on each input:
- Weight-sharing meta-network. ViTs natively support variable tokens but not variable channels; PRANCE introduces a meta-network that supports arbitrary channel widths for the Multi-Head Self-Attention and MLP layers, serving as the backbone for architectural decisions.
- PPO selector + “Result-to-Go” training. Jointly choosing structure and tokens is a combinatorial problem with a ~10^14 decision space. A lightweight selector trained with Proximal Policy Optimization makes the decisions, and a “Result-to-Go” mechanism models ViT inference as a Markov decision process to shrink the action space and mitigate delayed rewards.
PRANCE reduces FLOPs by ~50% while keeping only ~10% of tokens at lossless Top-1 accuracy, and is compatible with pruning, merging, and sequential pruning-merging. Code: github.com/ChildTang/PRANCE.