
SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration
Published in International Conference on Learning Representations 2026 (ICLR 2026), 2026
Recommended citation: Ye Li, Yuan Meng, Zewen Sun, Kangye Ji, Chen Tang, Jiajun Fan, Xinzhu Ma, Shu-Tao Xia, Zhi Wang, Wenwu Zhu. "SP-VLA: A Joint Model Scheduling and Token Pruning Approach for VLA Model Acceleration." ICLR 2026. https://arxiv.org/abs/2506.12723
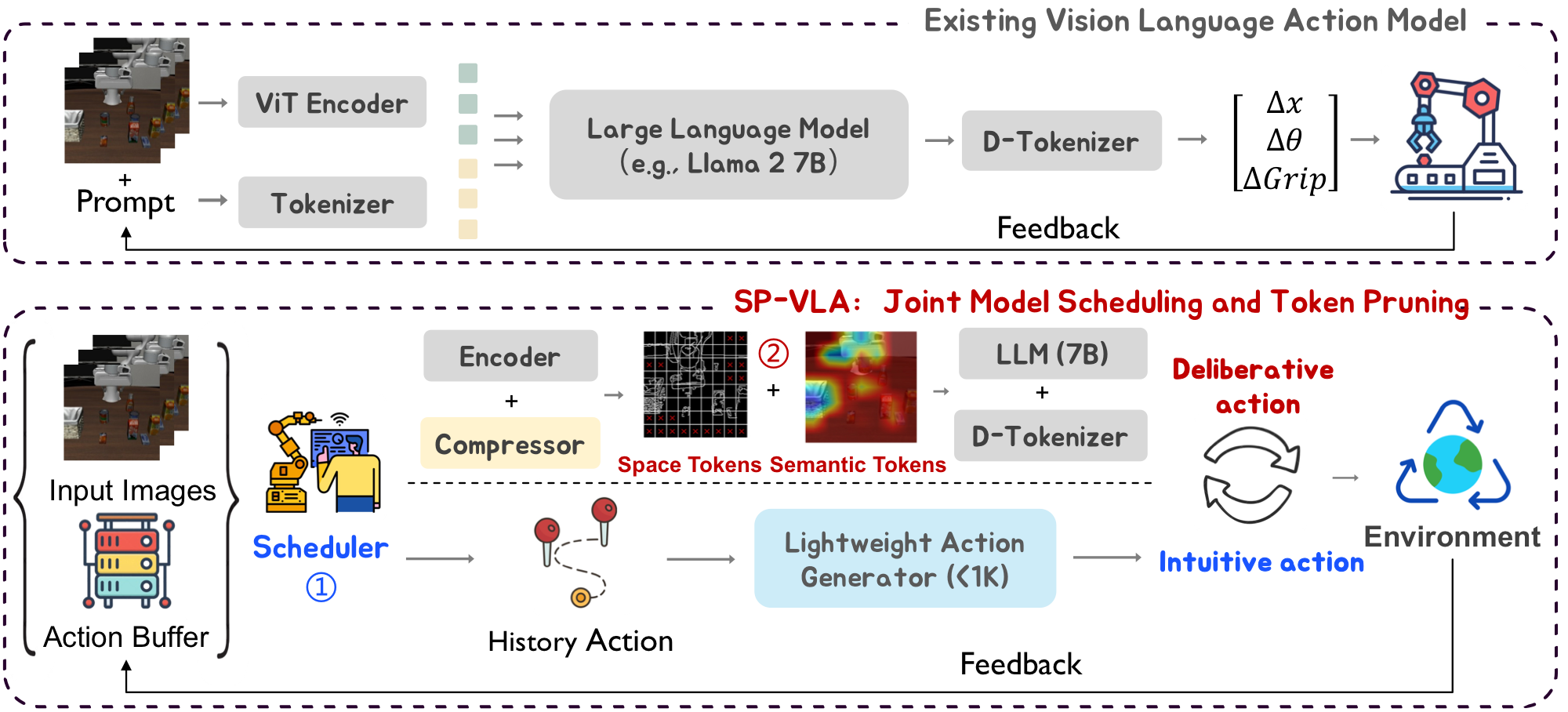
Vision-Language-Action (VLA) models have attracted increasing attention for their strong control capabilities, but their high computational cost and low execution frequency hinder real-time tasks such as robotic manipulation and autonomous navigation. Existing VLA acceleration methods focus on structural optimization while overlooking that these models operate in sequential decision-making environments, leaving temporal redundancy (in sequential action generation) and spatial redundancy (in visual input) unaddressed.
We propose SP-VLA, a unified framework that accelerates VLA models by jointly scheduling models and pruning tokens:
- Action-aware model scheduling. Inspired by human motion — focusing on key decision points while relying on intuition elsewhere — we categorize VLA actions into deliberative and intuitive, assigning the former to the VLA model and the latter to a lightweight generator, enabling frequency-adaptive execution.
- Spatio-semantic dual-aware token pruning. Tokens are classified into spatial and semantic types and pruned by their dual-aware importance (object contours via the Canny operator + accumulated attention), with a speed-adaptive threshold.
Together these guide the VLA to focus on critical actions and salient visual information, achieving effective acceleration while maintaining accuracy. Extensive experiments show 1.5× lossless acceleration on LIBERO and 2.4× on SimplerEnv, with up to 6% average performance gain; inference frequency and latency improve by 2.2× on SimplerEnv and 1.4× on LIBERO.