
TS-DP: Reinforcement Speculative Decoding for Temporal Adaptive Diffusion Policy Acceleration
Published in arXiv preprint, 2025, 2025
Recommended citation: Ye Li, Jiahe Feng, Yuan Meng, Kangye Ji, Chen Tang, Xinwan Wen, Shu-Tao Xia, Zhi Wang, Wenwu Zhu. "TS-DP: Reinforcement Speculative Decoding for Temporal Adaptive Diffusion Policy Acceleration." arXiv:2512.15773, 2025. https://arxiv.org/abs/2512.15773
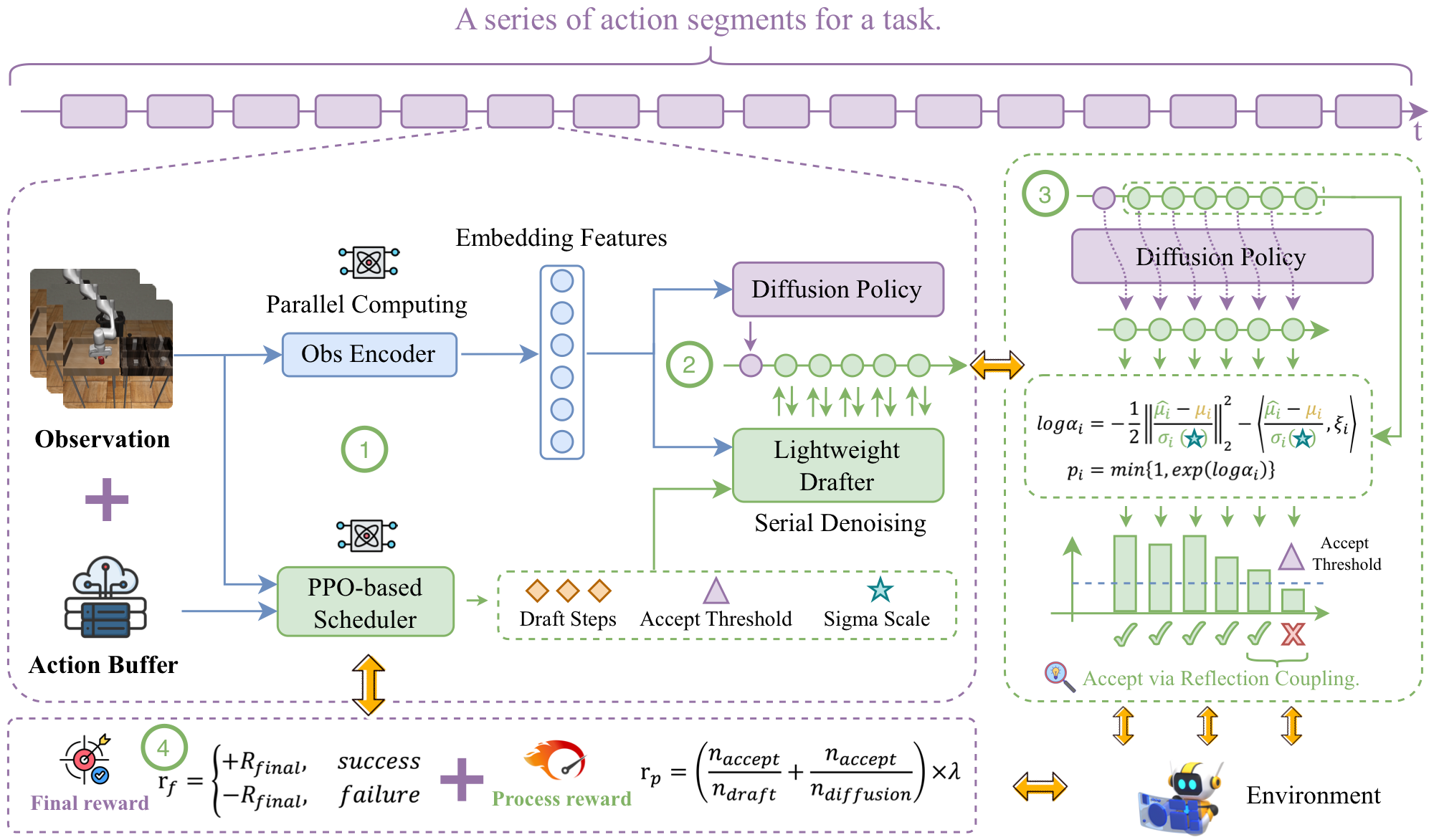
Diffusion Policy (DP) excels at embodied control but suffers from high inference latency, because each action requires many iterative denoising steps. Embodied tasks are also temporally non-uniform — difficulty varies over time — so they need a dynamic, adaptable amount of computation. Static, lossy accelerators (e.g., quantization) cannot meet this need, while speculative decoding offers a lossless and adaptive alternative that has been largely unexplored for DP.
TS-DP (Temporal-aware Reinforcement-based Speculative Diffusion Policy) is the first framework to enable speculative decoding for Diffusion Policy with temporal adaptivity:
- Distilled Transformer drafter. A lightweight drafter is distilled to imitate the base policy and replace its costly denoising calls, proposing candidate actions cheaply.
- RL-based scheduler. A reinforcement-learning scheduler adapts the speculative parameters to time-varying task difficulty, preserving accuracy while maximizing efficiency.
Across diverse embodied environments, TS-DP achieves up to 4.17× faster inference with over 94% accepted drafts, reaching 25 Hz real-time diffusion-based control without performance degradation.